Lebesgue constant (interpolation)
- For other uses, see: Lebesgue constant (disambiguation).
In mathematics, the Lebesgue constants (depending on a set of nodes and of its size) give an idea of how good the interpolant of a function (at the given nodes) is in comparison with the best polynomial approximation of the function (the degree of the polynomials are obviously fixed). The Lebesgue constant for polynomials of degree at most n and for the set of n + 1 nodes T is generally denoted by Λn(T). These constants are named after Henri Lebesgue.
Contents |
Definition
We fix the interpolation nodes x0, …, xn and an interval [a, b] containing all the interpolation nodes. The process of interpolation maps the function f to a polynomial p. This defines a mapping X from the space C([a, b]) of all continuous functions on [a, b] to itself. The map X is linear and it is a projection on the subspace Πn of polynomials of degree n or less.
The Lebesgue constant Λn(T) is defined as the operator norm of X. This definition requires us to specify a norm on C([a, b]). The maximum norm is usually the most convenient.
Properties
The Lebesgue constant bounds the interpolation error:
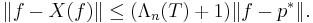
We will here prove this statement with the maximum norm. Let p∗ denote the best approximation of f among the polynomials of degree n or less. In other words, p∗ minimizes ||p − f|| among all p in Πn. Then
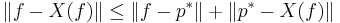
by the triangle inequality. But X is a projection on Πn, so p∗ − X(f) =X(p∗) − X(f) = X(p∗−f). This finishes the proof. Note that this relation comes also as a special case of Lebesgue's lemma.
In other words, the interpolation polynomial is at most a factor Λn(T) + 1 worse than the best possible approximation. This suggests that we look for a set of interpolation nodes with a small Lebesgue constant.
The Lebesgue constant can be expressed in terms of the Lagrange basis polynomials:
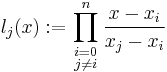
In fact, we have the Lebesgue function
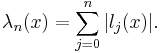
and the Lebesgue constant (or Lebesgue number) for the grid is its maximum value
![\Lambda_n(T)=\max_{x\in[a,b]} \lambda_n(x)](/2012-wikipedia_en_all_nopic_01_2012/I/ce24497ade888a342cbd047b7f7877c0.png)
Nevertheless, it is not easy to find an explicit expression for Λn(T).
Minimal Lebesgue constants
In the case of equidistant nodes, the Lebesgue constant grows exponentially. More precisely, we have the following asymptotic estimate
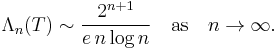
On the other hand, the Lebesgue constant grows only logarithmically if Chebyshev nodes are used, since we have
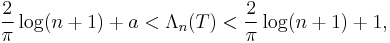
where a = 0.9625….
We conclude again that Chebyshev nodes are a very good choice for polynomial interpolation. However, there is an easy (linear) transformation of Chebyshev nodes that gives a better Lebesgue constant. Let ti denote the ith Chebyshev node. Then, define si = ti⁄cos(π⁄2(n+1)). For such nodes:
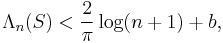
where b = 0.7219….
Those nodes are, however, not optimal (i.e. they do not minimize the Lebesgue constants) and the search for an optimal set of nodes (which has already been proved to be unique under some assumptions) is still one of the most intriguing topics in mathematics today. Using a computer, one can approximate the values of the minimal constants, here for the canonical interval [−1,1]:
-
n 1 2 3 4 5 6 7 8 9 Λn(T) 1.0000 1.2500 1.4229 1.5595 1.6722 1.7681 1.8516 1.9255 1.9917
There are several sets of nodes that minimize, for fixed n, the Lebesgue constant. Though if we assume that we always take −1 and 1 as nodes for interpolation, then such a set is unique. To illustrate this property, we shall see what happens when n = 2 (i.e. we consider 3 interpolation nodes in which case the property is not trivial). One can check that each set of nodes of type (−a,0,a) is optimal when √8⁄3 ≤ a ≤ 1 (we consider only nodes in [−1,1]). If we force the set of nodes to be of the type (−1,b,1), then b must equal 0 (look at the Lebesgue function, whose maximum is the Lebesgue constant).
If we assume that we take −1 and 1 as nodes for interpolation, then as shown by H.-J. Rack, for the case n = 3, the explicit values of the optimal nodes and the explicit value of the minimal Lebesgue constant are known.
Sensitivity of the values of a polynomial
The Lebesgue constants also arise in another problem. Let 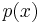 be a polynomial of degree
be a polynomial of degree  expressed in the Lagrangian form associated with the points in the vector
expressed in the Lagrangian form associated with the points in the vector 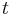 (i.e. the vector
(i.e. the vector 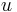 of its coefficients is the vector containing the values
of its coefficients is the vector containing the values 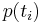 ). Let
). Let 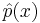 be a polynomial obtained by slightly changing the coefficients of the original polynomial to
be a polynomial obtained by slightly changing the coefficients of the original polynomial to 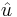 . Let us consider the inequality:
. Let us consider the inequality:
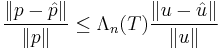
This means that the (relative) error in the values of will not be higher than the appropriate Lebesgue constant times the relative error in the coefficients. In this sense, the Lebesgue constant can be viewed as the relative condition number of the operator mapping each coefficient vector to the set of the values of the polynomial with coefficients in the Lagrange form. We can actually define such an operator for each polynomial basis but its condition number is greater than the optimal Lebesgue constant for most convenient bases.
References
- Brutman, L. (1997), "Lebesgue functions for polynomial interpolation — a survey", Annals of Numerical Mathematics 4: 111–127, ISSN 1021-2655
- Smith, Simon J. (2006), "Lebesgue constants in polynomial interpolation", Annales Mathematicae et Informaticae 33: 109–123, ISSN 1787-5021, http://www.emis.de/journals/AMI/2006/smith.pdf
- Rack, Heinz-Joachim (1984), "An example of optimal nodes for interpolation", International Journal of Mathematical Education in Science and Technology 15 (3): 355–357, doi:10.1080/0020739840150312, ISSN 1464-5211, http://www.informaworld.com/openurl?genre=article&issn=0020%2d739X&volume=15&issue=3&spage=355
- Lebesgue constants on MathWorld.